The HCI Research Group in Stuttgart
Our research covers a diverse set of topics related to human-computer interaction (HCI), virtual and augmented reality (VR/AR), and data visualization (VIS). The HCI group (opens in new tab) was founded in 2018 as the VR/AR group and is part of the Visualization Research Center (VISUS) (opens in new tab) and the Institute for Visualization and Interactive Systems (VIS) (opens in new tab) at the University of Stuttgart (opens in new tab) .
Director:
Prof. Dr. Michael Sedlmair
Address:
Visualization Research Center (VISUS), Allmandring 19, 70569 Stuttgart
(opens in new tab)
Imprint / Legal Notice
Research Focus
- Human-computer, human-data, and human-robot interaction
- Virtual and augmented reality
- Interactive visualization of data
- Basics of perception and cognition
Teaching
Together with the other groups in the institute, we contribute to teaching the bachelor's and master's programs in computer science through modules in human-computer interaction and visual computing. See our university website (opens in new tab) for more information on teaching.
Ongoing Projects
Finished Projects
- FFG ViSciPub (opens in new tab)
- HighAR (Carl Zeiss Stiftung)
- FarbAR (Carl Zeiss Stiftung)







































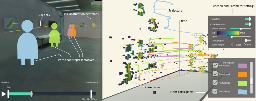
 VibeFM: Visual Exploration of FM Synthesis
VibeFM: Visual Exploration of FM Synthesis
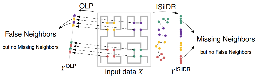

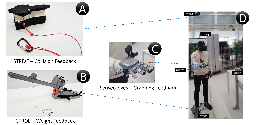
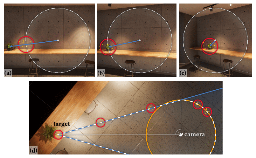
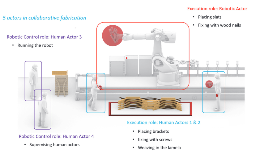
 The Ambivalent Experience of Eye Contact for People with Visual Impairments: Mechanisms and Design Challenges
The Ambivalent Experience of Eye Contact for People with Visual Impairments: Mechanisms and Design Challenges

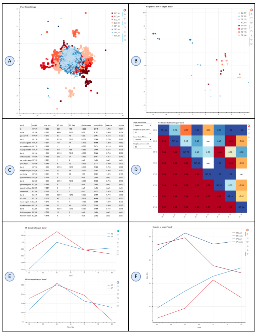

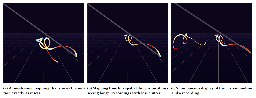
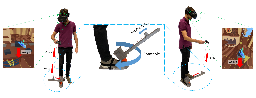
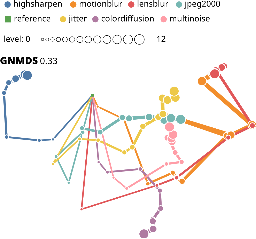
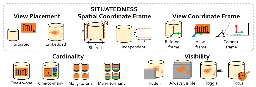
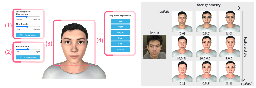
 A Large-Scale Quantitative Analysis of Avatars in VR and AR
A Large-Scale Quantitative Analysis of Avatars in VR and AR
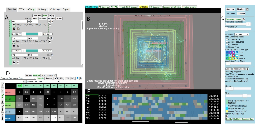









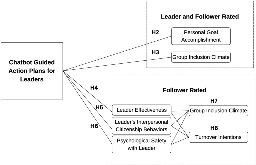
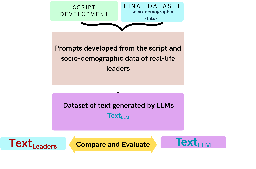
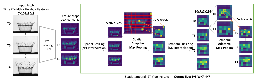
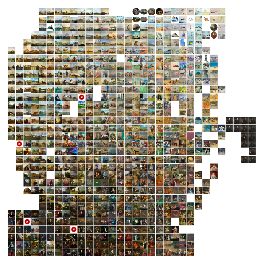



















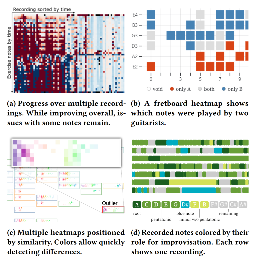
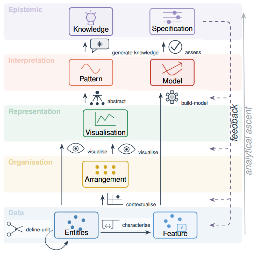
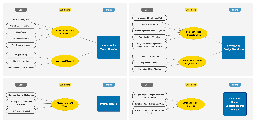
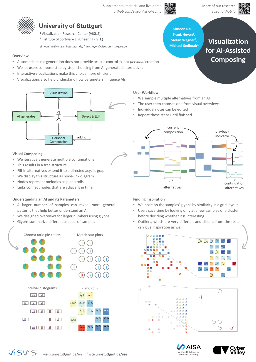
 MAICO: A Visualization Design Study on AI-Assisted Music Composition
MAICO: A Visualization Design Study on AI-Assisted Music Composition















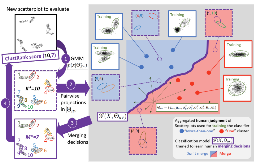
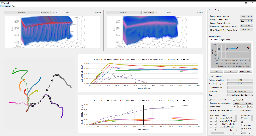
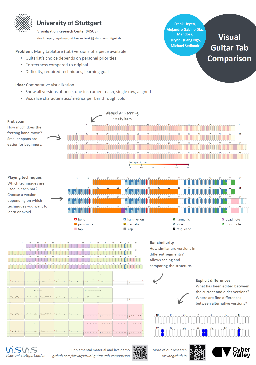
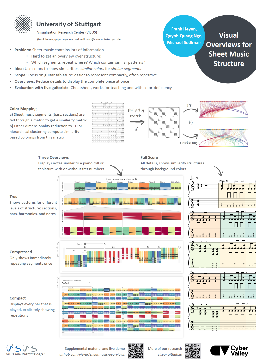










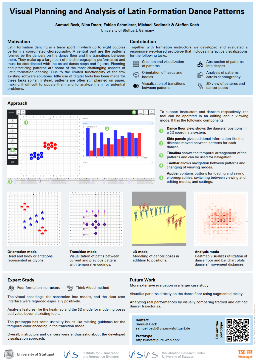

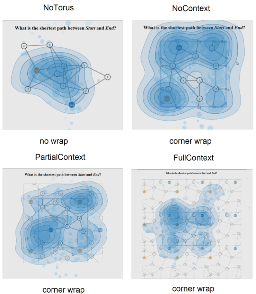



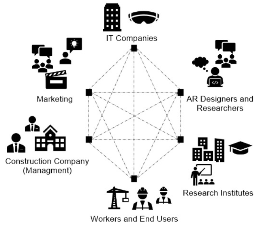



 Visualization for AI-Assisted Composing
Visualization for AI-Assisted Composing